Schema
The schema is the core data structure that you need to understand to become a Synth wizard. Schemas are JSON files
that encode the shape of the data you want to generate. All schemas are composed of generators that are assembled by
the user to create complex data structures.
It's a little involved, so let's start with a simpler example: JSON!
JSON#
If you've never actually seen how JSON is implemented under the hood, you may find this interesting.
One of the reasons for JSON's popularity is just how simple of a data structure it is. JSON is a recursive data
structure (just a tree but let's pretend we're smart) and can be defined in 8 lines of code (if you're wondering, this
is Rust's enum notation):
enum Value { Null, // null Bool(bool), // true Number(Number), // 42 String(String), // "Synth" Array(Vec<Value>), // [0, true, "a", ...] Object(Map<String, Value>), // { "name" : "Cynthia", "age" : 42 }}So every node in a JSON tree, is one of 6 variants. Recursion occurs where Arrays and Objects can have children
which are also one of 6 variants.
We've based the Synth schema on the same design. But, what does this look like when you need to capture far more complexity than the JSON schema?
Synth Schema Nodes#
Much like the Value node in a JSON tree, the Schema nodes in the Synth schema give us a recursive data structure
which Synth can use to generate data.
enum Schema { Null, Bool(BoolSchema), Number(NumberSchema), String(StringSchema), // here DateTime(DateTimeSchema), Array(ArraySchema), Object(ObjectSchema), SameAs(SameAsSchema), OneOf(OneOfSchema),}Each of these Schema variants, cover a bunch of different types of Schema nodes, just to give an example,
the StringSchema variant looks like this under the hood:
enum StringSchema { Pattern(RegexSchema), Faker(FakerSchema), Categorical(Categorical<String>), Serialized(SerializedSchema), Uuid(Uuid), Truncated(TruncatedSchema), Format(FormatSchema),}Where String types can be generated from regular expressions, faker providers, and so on.
For a comprehensive list see the String docs.
Writing Synth Schemas#
Schema nodes have different fields depending on the type of node. This makes sense, if you are generating Id's,
you're going to want to specify different parameters to if you are generating a date or a time.
However, all Schema nodes follow a similar template.
- There is a boolean
optionalfield, which tells Synth if a field is nullable or not. - Next there is a
typefield, which specifies which top-levelSchematype the node is (string,number,booletc.). Fields can often have asubtypewhich disambiguates certain types (for example is anumbera floatf64or an unsigned integeru64.) - Finally,
Schemanodes can have 0 or more fields which are specific to that node type. For more information refer to the documentation for that type.
{ "type": "number", "subtype": "f64", "range": { "low": 274.4, "high": 6597.5, "step": 0.1 }}A real life example#
In our example schema we have a namespace my_app which has 2 collections - transactions and users.
Below is a tree representation of the schema Schema tree:
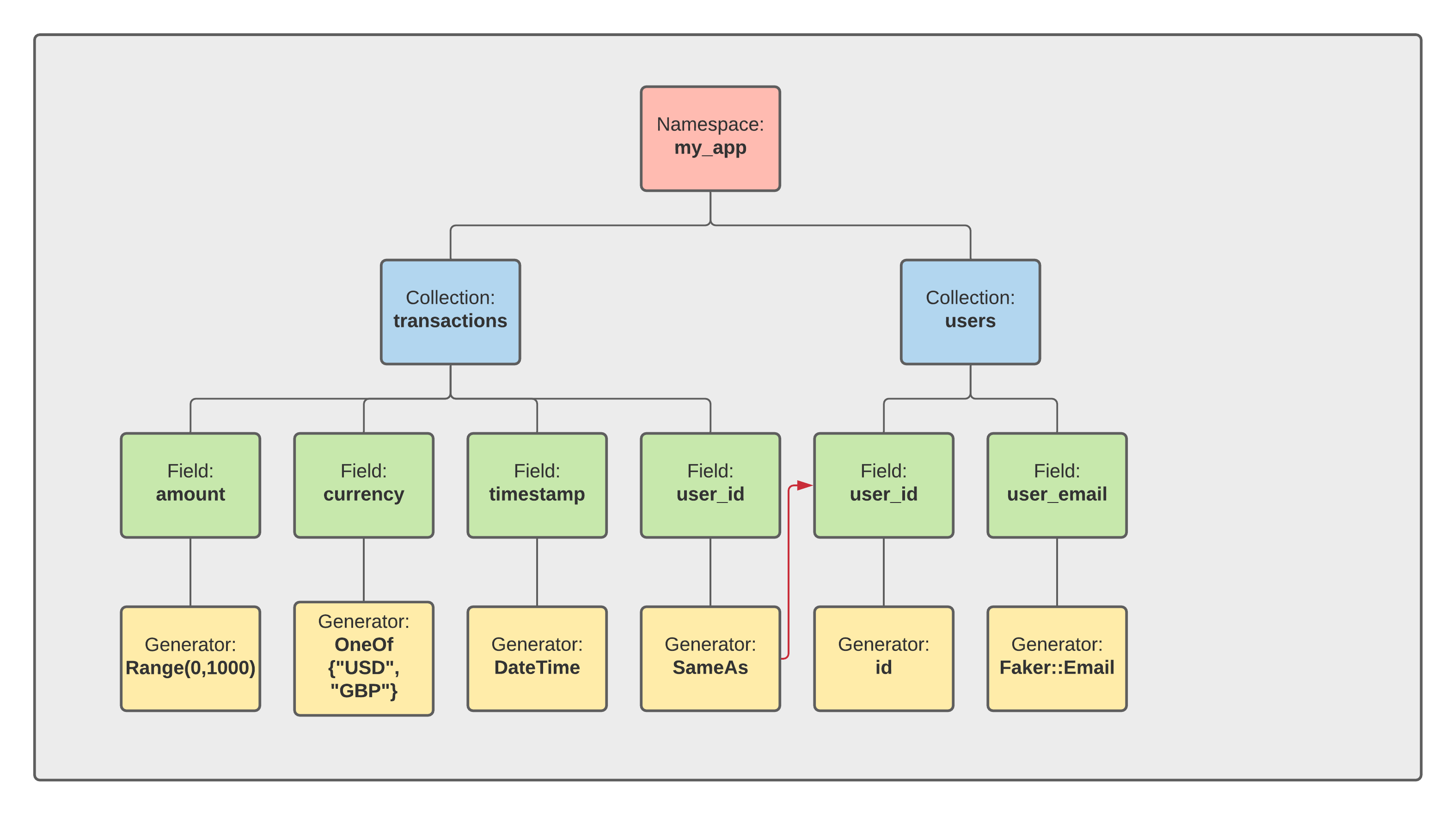
The corresponding namespace can be broken into 2 collections. The first, transactions:
{ "type": "array", "length": { "type": "number", "subtype": "u64", "range": { "low": 1, "high": 6, "step": 1 } }, "content": { "type": "object", "amount": { "optional": false, "type": "number", "subtype": "f64", "range": { "low": 0, "high": 1000, "step": 0.01 } }, "currency": { "type": "one_of", "variants": [ { "type": "string", "pattern": "USD" }, { "type": "string", "pattern": "GBP" } ] }, "timestamp": { "type": "date_time", "format": "%Y-%m-%dT%H:%M:%S%z", "begin": "2000-01-01T00:00:00+0000", "end": "2020-01-01T00:00:00+0000" }, "user_id": { "type": "same_as", "ref": "users.content.user_id" } }}And the second, the users collection:
{ "type": "array", "length": { "type": "number", "subtype": "u64", "range": { "low": 1, "high": 6, "step": 1 } }, "content": { "type": "object", "user_id": { "type": "number", "subtype": "u64", "id": { "start_at": 0 } }, "user_email": { "type": "string", "faker": { "generator": "safe_email" } } }}What's next#
The generators reference in this documentation is the best place to become familiar with all the different variants of schema nodes. This will let you write schemas for any of the data you might need.